Melodot: Incentive-compatible data availability layer
- Team Name: ZeroDAO
- Payment Address: 0xEBCDa7c73EB5Dd7a4314cFf395bE07EB1E24c046 (DAI)
- Level: 2
Project Overview 📄
Data Availability Layer
The current data availability layer scheme requires the assumption that the network has at least the minimum number of honest nodes.However, due to the need to prevent data retention attacks, the samplers are required to be anonymous, making it difficult to measure the number of samplers. At the same time, samplers are more concerned with data related to themselves, resulting in an uneven distribution of total active samplers over time. The assumption of a minimum number of honest nodes affects the robustness of the data availability layer.
Challenging issues in the data availability layer also include: who will perform distributed generation, who will reconstruct the data, who will store the data, how long will the data be stored, and how to ensure that these tasks are well done.
One possible approach is to delegate these tasks to consensus validators, but there is a lack of effective incentive mechanisms. For cost considerations, not performing distributed generation, data reconstruction, and data storage is the most profitable for validators. In addition, consuming too many resources of consensus validators is very unfavorable for scalability.
Melodot introduces the role of farmers by combining PoSpace, alleviating the system's dependence on the minimum number of honest nodes assumption, and completing an incentive-compatible distributed generation and data storage scheme. Consensus validators now act more like light clients, improving future scalability. You can learn more from this preliminary whitepaper.
Project Details
Architecture
Erasure Coding and KZG Commitment
Melodot uses 2D Reed-Solomon for data expansion, providing better sampling efficiency. It generates KZG commitments in the row direction, avoiding fraud proofs, similar to Ethereum's Darksharding. Block headers contain KZG commitments and data locations for different apps, allowing light clients to sample or download only data relevant to themselves.
Farmers
Farmers receive rewards through PoSpace, which is used to verify that participants have allocated a certain amount of storage space on their devices. The consensus mechanism is achieved through a time-memory trade-off approach, which has its origins in the Beyond Hellman paper and has been adopted for use in the Chia protocol. This method allows for a more efficient and secure consensus process compared to traditional energy-intensive mechanisms such as Proof of Work. Subspace improves PoSpace for storing "useful data" and is closely linked to KZG commitments. We are inspired by them, in contrast, Melodot's farmers receive rewards through PoSpace rather than reaching consensus. This incentive mechanism ensures that the network can still recover data when natural sampling samples are insufficient and guarantees data storage for at least a specific duration.
Farmers need to complete the distributed generation of specified data, expanding the data generated by block proposers in the column direction. They then calculate the challenge eligibility through the generated data, similar to Chia's filter, with only a small portion of farmers eligible to further search for solutions. This design reduces the computation load on farmers, avoids missing the submission of solutions, and allows farmers to devote more bandwidth and capacity resources to data availability sampling and storage. In addition, farmers are more inclined to generate all specified data in a distributed manner, as each chunk represents a potential lottery ticket.
Farmers use the committed space to store blob data and maintain its timeliness. New data receives more rewards, while expired data will not be rewarded. Upon obtaining challenge eligibility, farmers need to search for solutions in the stored data, including chunk, data proofs, space proofs, etc. The system adjusts the difficulty based on the reward claims situation. Ultimately, the rewards farmers receive are linearly related to the size of the stored data space and depend on whether they have correctly and promptly completed distributed generation and necessary data reconstruction.
Lifecycle
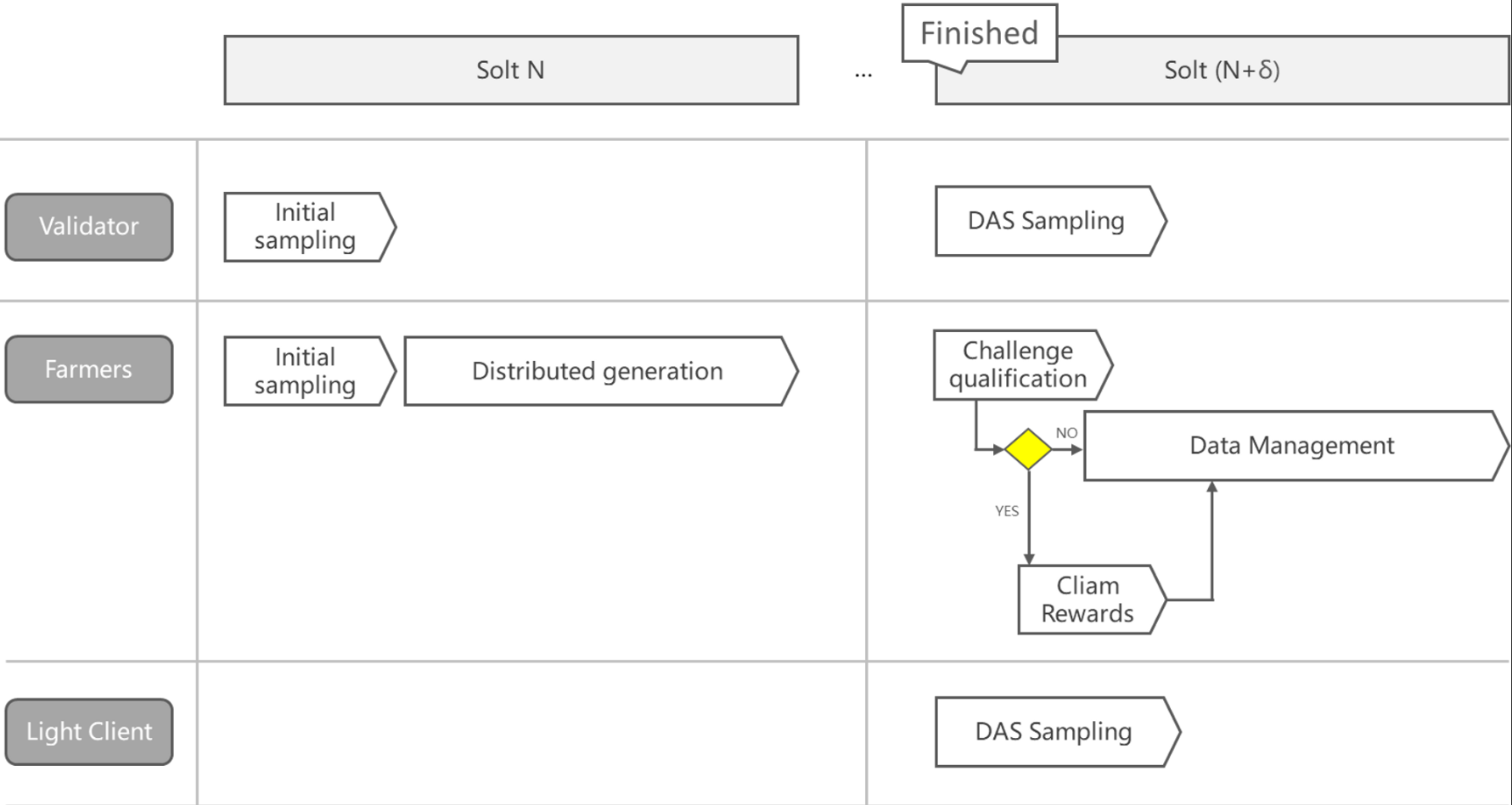
A complete blob transaction includes:
- Publishing a blob transaction, including the original KZG commitment
- Block builders collect blob transactions and build blocks, erasure code data, and generate new commitments to be added to the block header
- Consensus validators verify block validity and, along with farmers, perform preliminary availability sampling (not ensuring 100% validity, but with high probability of being valid), either rejecting or accepting the block
- Farmers use the block data, commitments, and proofs learned in the previous step to generate specified columns in a distributed manner
- When the block is finalized
- Farmers with challenge eligibility complete solutions and claim rewards
- Light clients and consensus validators perform sampling simultaneously
- Farmers obtain more specified data from the network for storage and delete expired data
Melodot is developed in phases, with the first phase not implementing the complete process.
Components
In this phase, we will implement the following core components:
-
Erasure-Coding
A core module for erasure coding and KZG based on rust-kzg, including expanding data and generating commitments and proofs, verifying blob, batch verifying blobs, recovering data, verifying the correct expansion of 2D commitments, and expanding column data and witnesses.
-
Melo-Store
Interfaces for registering and managing applications, uploading data, and storing data validity data.
-
Consensus-related extensions
excutive_das pallet: An extension of the frame-excutive pallet for scheduling block execution and validation related to DAS
system_das pallet: An extension of the frame-system pallet, adding new block header generation, actual data generation, and validation.
- Sampling Core
The core crate that actually performs sampling, which several clients in the system depend on. This includes data availability sampling, obtaining and propagating data from the DHT network, and managing data through rocksdb.
- Light Client
A light client that connects to the network and performs sampling based on the block state, including network implementation, distributed generation, data storage, and actual sampling.
Melo-PoSpace
A pallet for assigning distributed generation columns to farmers, verifying farmers' challenge chunk, and issuing rewards.
- Farmer Client
Connects to the network, obtains raw data, and performs distributed generation; obtains challenges from the chain and searches for solutions to claim rewards.
Non-Goals
The goal of the first phase is to minimally implement a usable system and will not fully implement the details described in the whitepaper. The main differences are:
PoSpace
In the first phase, we will only implement a preliminary version of PoSpace, not including the complete PoSpace process. Subspace has done an excellent exploration in this regard. In the next phase of development, we should be able to reuse much of their work.
Complete Distributed Generation
This phase does not include complete distributed generation. Users still need to submit actual data transactions, so farmers and validators do not need to perform the first phase of sampling.
Ecosystem Fit
Similar Projects
There are currently several data availability layer projects, including Ethereum Danksharding, Celestia, Avail, and Eigen DA. Our main difference from them is the introduction of farmers, which solves many tricky problems faced by the data availability layer. Unlike Danksharding, we decouple an independent data availability layer, which is the same principle as Polkadot not supporting smart contracts. Celestia uses a Merkle encoding pattern, requiring fraud proofs and additional assumptions, which we avoid. Avail's data layout uses a 1.5D scheme, which is unacceptable in terms of sampling efficiency, as detailed in the Melodot white paper. Eigen DA is an Ethereum re-collateralization layer implementation of a data availability scheme, with limited public information available, but it should be in the form of a DA committee, which has its applicable scenarios, but is not the same as Melodot.
Relationship with Polkadot and substrate
- With Melodot as a data availability layer, any parallel chain can easily become a Rollup settlement layer. Polkadot brings more secure interactions between settlement layers, significantly increasing Polkadot's capacity.
- Other teams can develop their own data availability layers based on Melodot.
Team 👥
Team members
- Daqin Lee
- Zhidong Chen
- Sober Man
Contact
- Contact Name: Daqin Lee
- Contact Email: lee@melodot.io
Team's experience
Daqin Lee: Full-stack Developer, Rust and Substrate Developer, core developer of Melodot.
Chen Zhidong: Full-stack Developer, Tesla Machine Learning Engineer, GoHack 2017 Hackathon First Prize, will serve as a technical advisor for Melodot.
Sober Man: Embedded Engineer, with years of backend and embedded development experience.
Team Code Repos
Development Status
ZeroDAO previously developed the Ourspace project, which is a reputation system utilizing social relationships and received support from W3F. After that, we shifted our focus to calculating all social networks in Web3. In this process, we found that they were either expensive to interact with or difficult to securely use on-chain. Through in-depth analysis, we summarized these issues as a lack of visibility. Therefore, we temporarily paused the development of Ourspace (we will continue to develop it later) and focused on researching the "visibility" issue, discovering that rollup technology is a good solution to this problem. The data availability layer is the first step in achieving this, and after extensive research, we designed Melodot. The work we have completed so far includes:
- Whitepaper: Completed a preliminary whitepaper.
- Research: We conducted some research on Rollup and data availability layer projects, and you can see the project list here.
Development Roadmap
Overview
- Total Estimated Duration: 4.5 months
- Full-Time Equivalent (FTE): 1.5
- Total Costs: 28,000 DAI
Milestone 1 — Erasure coding and KZG
- Estimated duration: 1 month
- FTE: 1
- Costs: 5,000 USD
| Number | Deliverable | Specification |
|---|---|---|
| 0a. | License | Apache 2.0 |
| 0b. | Documentation | We will provide both inline documentation of the code and a basic tutorial that explains how the new functionality works and how they are used. |
| 0c. | Testing and Testing Guide | Unit tests will completely cover the Core functionality to ensure functionality and robustness. In the guide, we will describe how to run these tests. |
| 0d. | Docker | We will provide Dockerfiles to demonstrate the full functionality of erasure coding and KZG commitments. |
| 1. | melo_erasure_coding | The core part of the system, including 2D erasure coding and KZG commitment-related primitives and common interfaces. |
Milestone 2 — Consensus
- Estimated duration: 1.5 months
- FTE: 1
- Costs: 7,000 USD
| Number | Deliverable | Specification |
|---|---|---|
| 0a. | License | Apache 2.0 |
| 0b. | Documentation | We will provide both inline documentation of the code and a basic tutorial that explains how a user can spin up a client, connect to the client management application and data through a browser, and create a local development chain. |
| 0c. | Testing and Testing Guide | Higher-level integration tests and unit tests for all modules. In the guide, we will describe how to run these tests. |
| 0d. | Docker | We will provide Dockerfiles to start nodes, create a local test network, and run all integration tests. |
| 1. | Substrate pallet: excutive_das | Modify the existing frame-executive pallet to support custom headers while ensuring all original tests continue to function. |
| 2. | Substrate pallet: system_das | Extend the frame-system pallet to support the creation of extended headers. |
| 3. | Substrate pallet: melo_store | A core pallet for handling data availability. Main features include: 1) Registering applications. 2) Allowing users to submit data metadata. 3) Validators accessing off-chain storage via OCW and reporting unavailable data. 4) Interface for creating extended block header. |
| 4. | melodot-client | A substrate client containing a complete data availability layer. The DAS core features include: 1) Accepting user-submitted blob_tx, verifying if the data is correctly encoded, submitting the transaction, and publishing the data to a peer-to-peer network 2) Validators retrieving data transactions from the transaction pool and attempting to fetch the data from DHT to save locally. |
Milestone 3 — Sampling
- Estimated duration: 1 month
- FTE: 1.5
- Costs: 7,000 USD
| Number | Deliverable | Specification |
|---|---|---|
| 0a. | License | Apache 2.0 |
| 0b. | Documentation | We will provide both inline documentation of the code and a basic tutorial that explains how a user can start a light client and connect to the network. |
| 0c. | Testing and Testing Guide | Core functions will be fully covered by comprehensive unit tests to ensure functionality and robustness. In the guide, we will describe how to run these tests. |
| 0d. | Docker | We will provide Dockerfiles to start a light client, connect to the local test network, and run all integration tests. |
| 0e. | Article | We will publish an article explaining how Melodot works, how to run a local test network, and how to run a light client. |
| 1. | Light client | A light client that connects to the network and efficiently performs sampling, stores sampling data, and maintains data availability confidence. |
| 2. | melo_sampling | A decoupled sampling module that provides core functionality related to data sampling. |
Milestone 4 — Farmer
- Estimated duration: 1 month
- FTE: 2
- Costs: 9,000 USD
| Number | Deliverable | Specification |
|---|---|---|
| 0a. | License | Apache 2.0 |
| 0b. | Documentation | We will provide both inline documentation of the code and a basic tutorial that explains how a user can run a farmer client and earn rewards. |
| 0c. | Testing and Testing Guide | Core functions will be fully covered by comprehensive unit tests to ensure functionality and robustness. In the guide, we will describe how to run these tests. |
| 0d. | Docker | We will provide a Dockerfile that can be used to test all the functionality delivered with this milestone. |
| 0e. | Article | We will publish an article explaining the farmer part and the future plans for Melodot, as well as how to run a farmer client. |
| 1. | melo_farmer | Implementation of the farmer client, used to connect to the melodot-client, solve challenges, and distribute and store data. |
| 2. | melo_PoSpace | A pallet used to assign distributed generation tasks to farmers and distribute rewards to farmers. |
Future Plans
In the near future, we plan to establish a company as the core development team. Our long-term plan is to build the entire ecosystem through a DAO, and we have already formulated a centralized version of the DAO to be developed after the launch of the Melodot testnet.
Our short-to-medium-term plan (6 months) includes:
Melodot
- Launch the testnet
- Identify and eliminate all possible security threats
- Complete the full PoSpace and distributed generation
SDK
- Develop an SDK based on Substrate for quickly launching settlement layers and sequencer
Additional Information➕
How did you hear about the Grant Program?
Web3 Foundation website
- Previous grant applications
We have previously applied for ZeroDAO-node, which has now been renamed to (ourspace).